Jak jsem sestavil svůj Stínový kabinet - návod na znalostní systém
V předchozím článku jsem popisoval svou cestu k roli architekta řešení. V rámci projektu “Stínový kabinet” jsem totiž zjistil, že psaní kódu lze dnes plnohodnotně nahradit pouhým dialogem s AI. Moje myšlenky a systémová architektura se tak začaly transformovat přímo ve fungující nástroj.
Dnes se podíváme na to, jak tento systém vypadá v praxi, bude to více technický návod, pokud byste si chtěli vytvořit svůj nástroj. Ukážu vám konkrétní řešení, které mi pomáhá s marketingovou strategií a rozhodováním při konzultacích pro klienty.
Anatomie atomu
Základní stavební jednotkou celého mého řešení nazývám “Atom”. Atom je maličký, strukturovaný kousek informace – není to celý dokument ani odstavec textu, je to jedna konkrétní myšlenka s jasně definovanými metadaty. Vycházím z myšlenky Zettelkasten a knihy Jak si dělat chytré poznámky.
Atomy mají oproti hledání v dokumentech přes fulltext výhodu, že již nesou strukturovaná metadata. Fulltext najde slovo v dokumentu, ale neřekne, jestli je to rozhodnutí nebo jen poznámka.
Co atom obsahuje:
Každá myšlenka v systému má svou “identitu” – ví, čím je (fakt, rozhodnutí, insight), odkud pochází, s čím souvisí, a hlavně – jak dlouho platí. Systém pracuje s časovou degradací informací. Každá myšlenka má svůj “poločas rozpadu” a váhu, která se dynamicky mění. Co platilo v roce 2024, má dnes pro systém poloviční relevanci, aniž bych mu to musel říkat.
Atomy nejsou izolované. Tvoří síť propojení – jedno rozhodnutí odkazuje na fakta, která ho podpořila. Insight odkazuje na data, ze kterých vzešel. Když se změní zdrojový fakt, vím, která rozhodnutí jsou tím ovlivněna.
Pět typů atomů
V úvodním článku jsem popsal pět typů atomů - typů informací: FACT, DECISION, INSIGHT, ACTION a ENTITY. Tady se zaměřím na to, co tabulka neukazuje – časovou degradaci a propojení, které popisuji výše.
Proces destilace = získávání relevantních informací
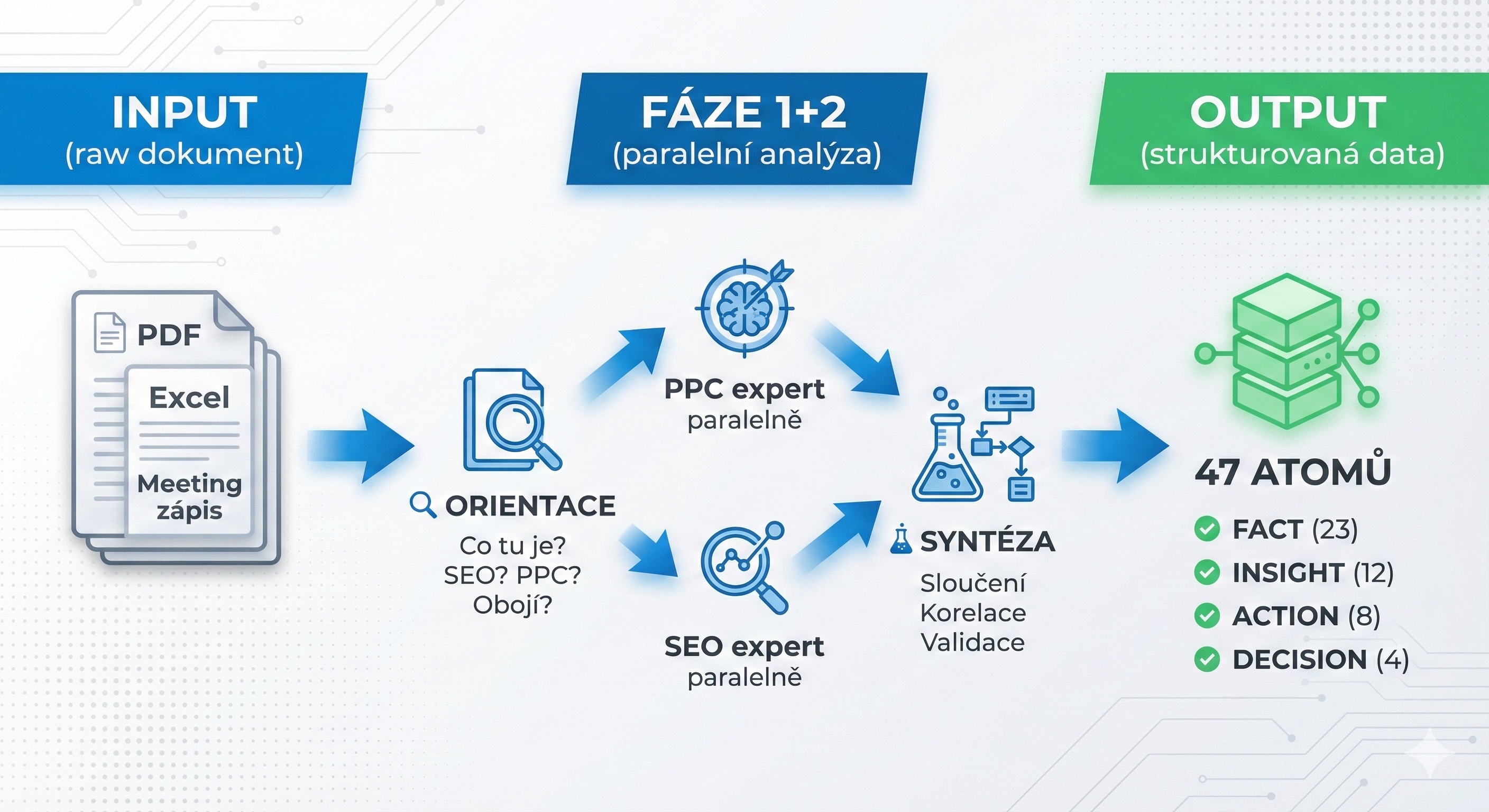
Základem pro tvorbu atomů je “destilace”. Nazval jsem si to proto, že vlastně destiluji velké dokumenty, abych z nich dostal tu pravou kvalitu - to podstatné. Destilace je proces, kterým z dokumentu vznikají atomy. Dám systému PDF, Excel, přepis meetingu – cokoliv – a on automaticky extrahuje strukturované informace.
Když mám dokument, který obsahuje SEO data i PPC metriky i analytiku, nástroj to sám rozpozná a spustí všechny relevantní agenty paralelně – v jedné message. Tím šetřím čas (3 agenti běží stejně dlouho jako 1) a dostanu komplexnější pohled.
Jak destilace funguje
Celý proces není jeden prompt, ale komplexní pipeline, která má tři hlavní fáze:
1. Kontextová orientace
Systém nejdřív zjišťuje, na co se dívá. Rozpozná, jaké domény dokument obsahuje – zda jde o PPC, SEO, analytiku, nebo kombinaci všeho. Podle toho určí, které specialisty potřebuje zavolat. Není to jednoduchá keyword detekce – systém chápe kontext a umí rozlišit, kdy je zmínka o SEO relevantní a kdy je jen okrajová.
2. Paralelní expertní analýza
Spuštění specializovaných “ministrů” – každý analyzuje dokument ze svého úhlu pohledu. PPC expert hledá jiné věci než SEO expert. Běží paralelně, takže čas je stejný jako pro jednoho. Každý specialista má vlastní znalostní bázi s checklisty, benchmarky, best practices. Nejen že čte – porovnává s tím, co “ví”.
3. Syntéza a křížová validace
Výstupy od specialistů se slučují. Systém hledá mezioborové korelace – když SEO hlásí pomalé stránky a Analytics ukazuje vysoký bounce rate na stejných URL, vznikne propojený insight. Duplicity se odstraní, konfliktní informace se označí.
Mezi každou fází je “hlídač”, který proces zastaví, pokud data nejsou dostatečně kvalitní. Systém radši řekne “potřebuji víc informací” než aby produkoval nekvalitní výstupy.
Příklad výstupu
Mám 20stránkový marketingový plán z workshopu. Napíšu jeden příkaz. Za dvě minuty dostanu strukturovaný výstup:
- 47 nových atomů – fakta, rozhodnutí, insighty, akční úkoly.
- Mezioborové korelace – systém našel souvislost mezi PPC náklady a prodeji, mezi rychlostí stránek a bounce rate.
- Validační report – duplicity sloučeny, chybějící data označena, křížové odkazy vytvořeny.
Za rok, až budeme opět s firmou něco řešit, nebudu hledat v desítkách zápisů. Systém mi vrátí relevantní atomy s odkazy na zdroje.
Chytré využití modelů
Ne každá část procesu potřebuje nejsilnější (a nejdražší) model. Systém automaticky vybírá, kdy použít rychlý levný model a kdy těžkou artilerii. Jednoduché úkoly jako klasifikace nebo formátování zvládne menší model. Komplexní analýzy a syntézy dostane silnější.
Když výstup nesplňuje kvalitativní práh, systém automaticky přepne na silnější model a fázi zopakuje. Je to záchranná síť, která zajišťuje konzistentní kvalitu bez mého zásahu.
Systém také umí správně zpracovat různé formáty – PDF, Excel, CSV. Rozpozná strukturu dokumentu, přečte text z obrázků, zachová schéma tabulek. Model pak dostane čistá, strukturovaná data místo raw textu.
Specializace vs. univerzalita v praxi
Proč mám Stínový kabinet desítek ministrů místo jednoho univerzálního poradce? Praktický důvod: kvalita výstupu.
Když destiluju marketingový plán, který obsahuje SEO + PPC + Analytics data, spustím paralelně tři specializované agenty. Každý má vlastní znalostní bázi se stovkami kontrolních bodů. Výsledek: 28 atomů s hlubokými insights.
Když stejný dokument pustím přes obecný agent, dostanu 22 atomů – většinou jen přepsaná čísla z dokumentu. Chybí cross-domain korelace, chybí porovnání s benchmarky, chybí identifikace problémů. Zkoušel jsem si to.
Proč? Specializovaný agent ví, co hledat. PPC agent nejen přečte “PNO 8”, ale okamžitě identifikuje, že to je pod průměrem pro e-commerce. A že se to liší oproti předchozímu období. SEO agent vidí “LCP 4,2s” a ví, že limit je 2,5s, tak mě na to upozorní a naplánuje mi úkol, aby se stránka zkontrolovala. Obecný agent by jen přepsal čísla bez kontextu.
(Více o teorii specializace najdete v článku o agentní architektuře)
Jak funguje stínový kabinet
Postupně jsem si vybudoval knihovnu ~50 agentů – můj stínový kabinet poradců. Funguje to jako ve firmě. Mám “generální ředitele” pro jednotlivé oblasti, kteří úkol rozpadnou a rozdají konkrétním specialistům. Já mluvím jen s ředitelem, on mi dodá výsledek od týmu.
Díky tomu se nestane, že by copywriter dělal technické SEO. Každý specialista má jasně vymezenou oblast a checklist, co kontrolovat.
Praktický příklad:
Dostanu 50stránkový report. Napíšu jeden příkaz. Systém:
- Rozpozná, jaké oblasti dokument pokrývá
- Spustí relevantní “ředitele” paralelně – běží současně, ne postupně
- Každý ředitel deleguje práci svým specialistům
- Výstupy se sloučí, hledají se mezioborové korelace
- Vznikne strukturovaný výstup s propojenými atomy
Celý proces běží 2-4 minuty – díky paralelizaci. Kdybych specialisty volal postupně, trvalo by to 15+ minut.
Začal jsem se 2 agenty. Dnes jich mám desítky, ale přidával jsem je podle potřeby – když jsem narazil na problém, který stávající agenti neuměli.
Jak učím systém novým věcem
Tohle mě baví nejvíc – systém se neustále učí a zlepšuje. Nejde o “nastavil a zapomněl”, ale o živý proces.
Trvalá paměť vs. opakované dotazy
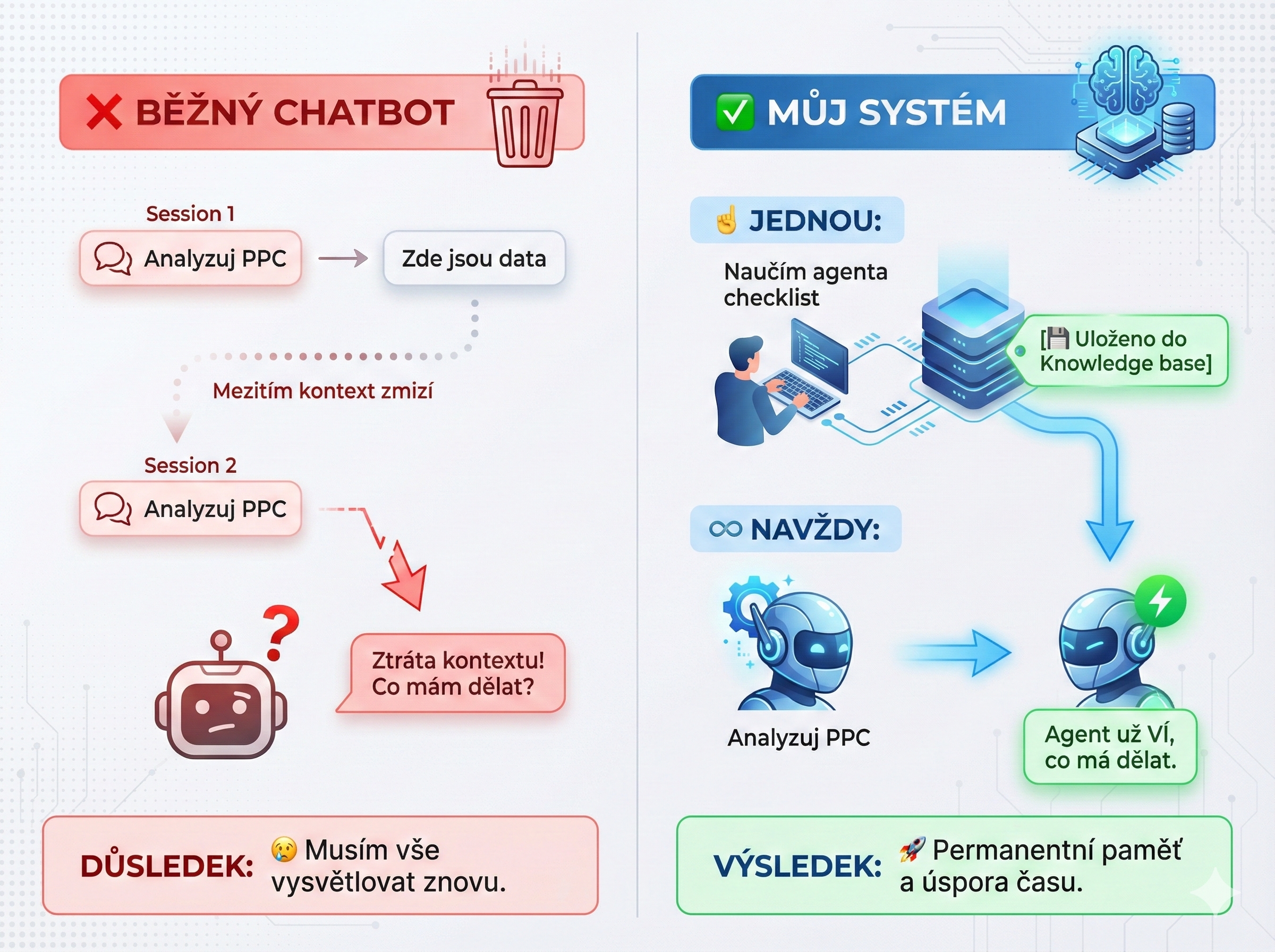
Špatný přístup (běžný chatbot):
`Session 1:
User: "Analyzuj PPC kampaně"
Bot: "Pošli mi data"
User:
Bot:
Session 2: (druhý den)
User: "Analyzuj další kampaně"
Bot: "Pošli mi data" ← ZNOVU!
User:
`Správný přístup (agent s knowledge base):
`Jednou:
User: "Tady máš checklist PPC auditora"
System:
Navždy:
User: "Analyzuj PPC kampaně"
Agent:
`Živá paměť místo statických promptů
Moji agenti nemají jen obecné znalosti z tréninku modelu. Každý specialista má k dispozici mnou vybudované, neustále aktualizované “manuály”. Když se změní best-practice v PPC, upravím jeden soubor a agent to okamžitě ví. Nespoléhám na paměť ChatGPT, ale na externí znalostní bázi.
Systém navíc používá mechanismus Context Compacting – při dlouhých sessions si “dělá poznámky” o tom, kde přesně skončil. Díky tomu můžu pracovat hodinu bez přerušení, aniž by se ztratil kontext. Ethan Mollick ve svém článku o Claude Code popisuje, jak nechal agenta pracovat 84 minut autonomně – systém mezitím vytvořil stovky souborů bez jediného dotazu. Klíčem byla jasná specifikace úkolu a správně nastavené skills.
Příklad – PPC auditor:
Měl jsem roky budovaný checklist s 347 kontrolními body pro PPC audit. Co kontrolovat, jaké metriky sledovat, co jsou Quick Wins. Tohle všechno jsem “naučil” agenta.
Teď když spustím PPC audit, agent automaticky:
- Načte kompletní znalostní bázi do kontextu
- Systematicky projde všechny oblasti
- Identifikuje priority podle dopadu a náročnosti
Já nemusím pamatovat checklist ani mu ho pokaždé vysvětlovat. Agent to prostě ví – a když najdu nový vzorec z projektu, přidám ho do znalostní báze a příště už ho zná.
Učení z dokumentace i praxe
Další příklad – Performance Max kampaně. Neměl jsem v tom hlubokou expertízu. Ale existuje dokumentace, existují best practices.
Nechal jsem systém nastudovat oficiální zdroje a vytvořit specializovaného agenta. Pak přišel první reálný projekt. Agent pomohl s analýzou, ale našel jsem věci, které dokumentace neřešila – praktické problémy z terénu.
Přidal jsem je do znalostní báze. Příště už je agent znal. Tohle je ta síla – kombinace teoretických znalostí z dokumentace a praktických zkušeností z projektů. Agent se učí z obojího.
Když upravím znalostní bázi, agent to při příštím volání automaticky použije. Nemusím mu nic vysvětlovat jako v chatu – prostě to ví.
Proč to funguje lépe než “paměť” v ChatGPT
ChatGPT má Memory funkci – “pamatuje si” konverzace. Ale to mi nestačí, jak jsem psal v předchozím článku. Můj přístup je zásadně jiný.
Běžná AI paměť: Zapamatuje si útržky z konverzací. Může zapomenout. Nelze sdílet mezi projekty. Nevíte, co si vlastně pamatuje.
Můj přístup: Agent si při každém volání načte kompletní znalostní bázi. Systematicky projde checklist. Znalosti jsou permanentní a verzované. Stejnou bázi sdílím mezi projekty.
Klíčový rozdíl: nemusím nic opisovat ručně. Agent si znalosti načte sám. A když něco změním, příště už to ví – bez vysvětlování.
Existující nástroje – ChatGPT Projects, Gemini Gems, NotebookLM – umožňují nahrát dokumenty a ptát se na ně. Ale jsou pasivní. Nástroj se sám neučí, nevylepšuje, nepřidává nové znalosti.
Multiagentní frameworky slibují orchestraci, ale většina je postavená na vektorovém, kontextovém vyhledávání – hodíte tam dokumenty a ono to “nějak” najde relevantní části - mělo by to poznat při dotazu PPC, že to má nějaký vztah k termínu “placená reklama”. Jenže já nepotřebuji “nějak”. Potřebuji rozlišit fakt od rozhodnutí. Potřebuji vidět, kdy informace vznikla a kdy expiruje. Potřebuji síť propojení.
Hlavně – Semafor spolehlivosti odpovědí. Žádný z těch nástrojů neměl mechanismus, který by explicitně řekl “tady si nejsem jistý, protože mi chybí data”. To pro mě jako stratéga byla zásadní věc.
Možná stavím po svém. Ale ta odlišnost mi dává smysl.
Proč AI nemůže řídit AI
Největší překvapení při stavbě? LLM je chytřejší než naplánovaný proces… a proto od něj uhýbá.
Napsal jsem workflow s deseti fázemi, každá má validaci. Spustím. Model přeskočí jednu fázi, sloučí další dvě dohromady, “vynechá validaci protože to není nutné”. Pak mi vrátí špatný výstup, který nesplňuje formát.
Problém: Jazykový model je kreativní. Když má workflow “Extract → Validate → Save”, může rozhodnout: “Uživatel nechce validaci, přeskočím ji.” Nedělá to naschvál – je to probabilistické, nepředvídatelné chování.
Řešení: Orchestrační vrstva
Velké zjištění bylo, že AI nemůže řídit AI. Nad modely musí stát pevná logická vrstva, která vynucuje pravidla. Můj systém nenechává modely “bloumat”. Má pevně dané mantinely – a pokud model uhne, systém ho vrátí do latě.
Je to kombinace tvrdé logiky a kreativní AI:
- Tvrdá logika řídí pořadí kroků, volá správné specialisty, validuje výstupy, ukládá checkpointy
- AI řeší to, v čem je dobrá: analýzu obsahu, interpretaci kontextu, generování výstupů
Model nedostane volnost rozhodnout, co přeskočit. Dostane jasný úkol a vrátí výstup. O zbytek se stará orchestrace.
Proč to funguje
Činnost Kdo to dělá Proč
Validace formátu souboru skripty if/else logika, 100% spolehlivost
Počítání souborů v adresáři skripty Jednoduché, rychlé, předvídatelné
ICE skóre (Impact × Confidence × Ease) skripty Matematika, ne jazykový úkol
Klasifikace typu dokumentu LLM Potřebuje pochopení kontextu
Extrakce klíčových zjištění LLM Vyžaduje interpretaci textu
Generování cross-domain insights LLM Kreativní myšlení
Pomůcka:
- Pokud to jde napsat jako if (condition) { action } → skripty
- Pokud to vyžaduje pochopení kontextu → LLM
Autonomní běh bez interakce
Orchestrace může běžet i plně autonomně bez nutnosti lidské interakce v průběhu procesu. To je užitečné pro:
- Hromadné zpracování – zpracování 50 dokumentů přes noc
- Naplánované audity – automatické audity každý týden
Tohle je teprve začátek. Podle 2026 Agentic Coding Trends Report od Anthropic se horizonty úkolů rozšiřují z minut na dny nebo týdny. Agenti, kteří běží autonomně celé dny, monitorují změny a iterují na řešeních bez lidské intervence – deterministická, vždy stejná orchestrace a checkpointy jsou základem pro tyto dlouhodobé workflow.
Workflow v praxi: Od příkazu k výsledku
Praktický průchod procesem – jak to funguje:
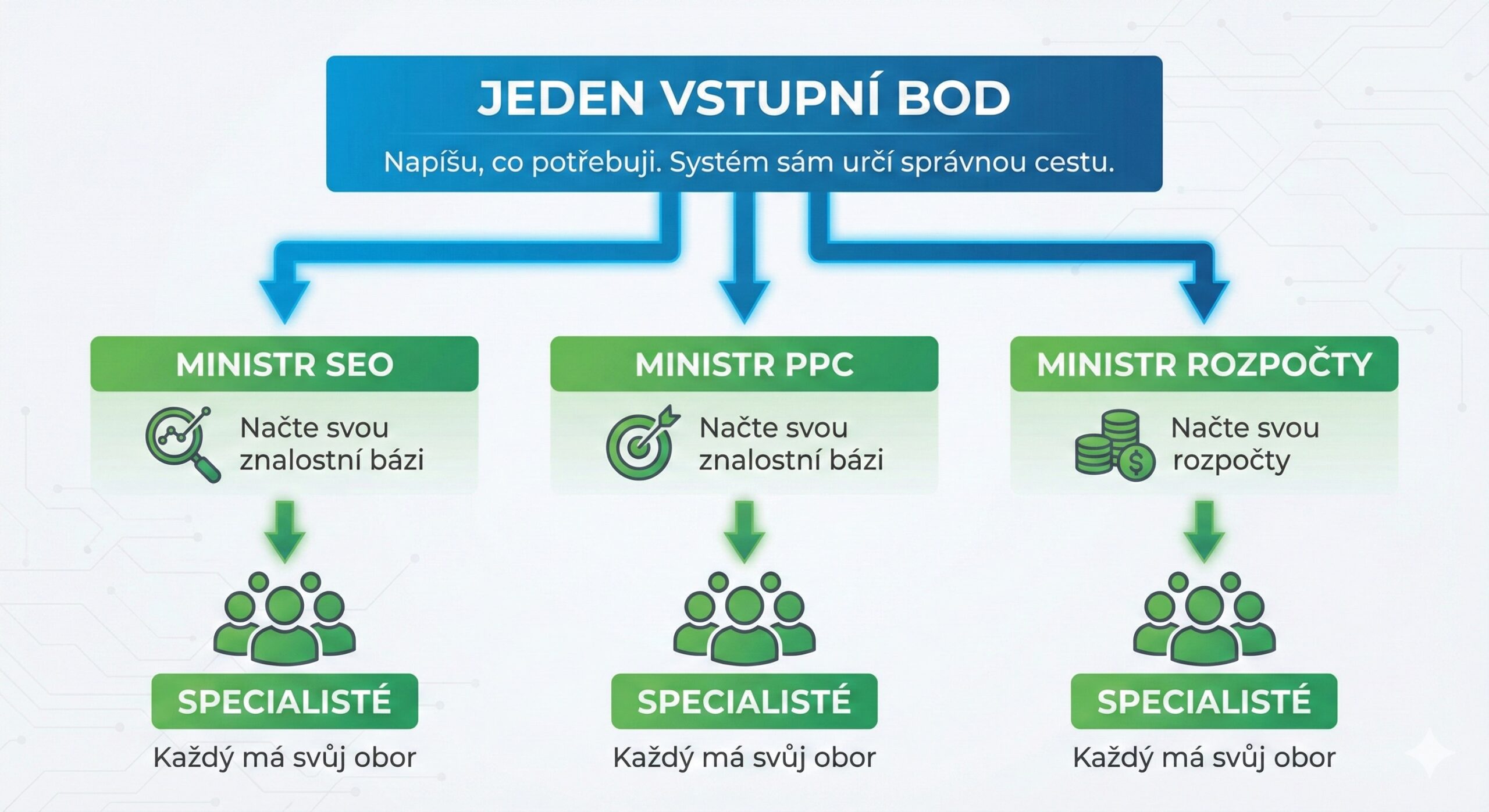
Tato hierarchie mi pomáhá udržet přehled. Nemusím přemýšlet “kterého ministra mám oslovit”. Napíšu co potřebuji a šéf kabinetu sám určí správnou cestu a deleguje práci.
Tvorba doporučení a strategií
Pak na to navazuje úplně samostatná a podstatná fáze – tvorba doporučení a strategií. Zde mi můj “Stínový kabinet” začne dávat odborná doporučení. Upozorňovat mě na slabá místa, sporovat dřívější rozhodnutí.
V dřívějších fázích jsem si vydestiloval informace, ale nyní budu chtít, aby mi z nich udělal nějaký obrázek, vyřešil mi nějaký konkrétní “úkol”. Bude tvořit “taktiky” a “strategie” proto, aby mi dal lepší kontext, vhled do situace, obsáhl více témat současně, a já měl lepší podklady pro svá vlastní rozhodnutí.
Úkol je třeba celkem triviální: “Najdi mi, jaké kampaně v PPC mají horší výkon v tomto roce než roce minulém.” Nebo: “Navrhni mi na základě top produktů a top hledaných slov nové landing page pro web.” Zde mi ušetří spoustu práce tím, že mě na dané kampaně či potenciální témata pro stránky upozorní, a já mohu jen jít a zkontrolovat doporučení.
Proces tvorby doporučení
Podobně jako destilace, i tvorba doporučení má strukturovaný workflow. Tři hlavní bloky:
1. Porozumění a příprava
Systém nejdřív zjistí, o co jde – jaká témata dotaz pokrývá, jaká data jsou k dispozici, co případně chybí. Pokud je dotaz příliš široký, zeptá se na priority. Pokud chybí kritická data, zastaví se a řekne co potřebuje.
2. Paralelní analýza a syntéza
Specialisté analyzují problém každý ze svého úhlu – paralelně, ne postupně. Výstupy se pak slučují, hledají se synergie a konflikty mezi oblastmi. Vzniká jednotný strategický pohled, ne izolované odpovědi od jednotlivých expertů.
3. Prioritizace a akční plán
Doporučení se prioritizují podle dopadu, spolehlivosti a náročnosti. Výstupem je strukturovaný akční plán s cíli, klíčovými výsledky a metrikami. Systém také navrhne, jak se může sám vylepšit na základě toho, co se naučil.
Hybridní zpracování: Skripty + LLM
Místo jednoho velkého promptu mám definované fáze s validacemi mezi nimi. Klíčové poučení: ne vše má dělat model.
Kdy skripty, kdy LLM
Systém umí rozlišit, kdy je potřeba “kalkulačka” a kdy “analytik”. Tvrdá data se zpracovávají matematicky přesně, trendy a souvislosti hledá AI. Díky tomu se mi nestane, že by model halucinoval součet nákladů.
Příklad hybridního zpracování:
Před jakoukoli analýzou proběhne audit dat – co mám, co mi chybí, jak jsou data stará. Tohle běží rychle a deterministicky – žádné “možná” nebo “asi”. Buď data jsou, nebo nejsou. Buď jsou aktuální, nebo zastaralá.
Pak přijde matematika – výpočet skóre, prioritizace, srovnání s benchmarky. Opět bez AI – je to čistá logika, která musí být 100% spolehlivá.
AI pak dostane připravená, strukturovaná data. Ne 10 000 řádků raw exportu, ale souhrn klíčových metrik. Její práce je hledat souvislosti, interpretovat trendy, navrhovat hypotézy – kreativní myšlení, ne počítání.
Proč to funguje
Kontrolní body mezi fázemi – po každé fázi validuji výstup, pokud něco nefunguje, workflow se zastaví. Specializace kontextu – každý agent dostane jen relevantní data. Transparentnost – vím přesně, kdo co udělal, pokud je výstup špatný, vím, kterého agenta ladit.
Výstupy jsou vodítka, ne pravda
Důležité upozornění: výstupy z tohoto procesu jsou pro mě stále jen doporučení – vodítka, místa odkud začít přemýšlet. Rozhodně to nejsou finální informace, které bych vzal a poslal dál jako hotovou práci.
Systém mi pomáhá rychleji najít relevantní data, identifikovat vzory, navrhnout priority. Ale finální rozhodnutí dělám já. Kontroluji zdroje, ověřuji logiku, doplňuji kontext, který systém nemá. Je to marketingový asistent, který mi připraví podklady – ne automat, kterému slepě věřím.
Anti-halucinační ochrana
Běžná AI ráda halucinuje. Můj systém má několik vrstev obrany.
Požadování kritické analýzy. AI má přirozenou tendenci k lichotivosti – říká vám, co chcete slyšet. Řešením je požádat systém o dvě verze – optimistickou i kritickou. Teprve kritická analýza odhalí slabá místa, která by jinak zůstala skrytá.
Povinné citace zdrojů. Nikdy netvrdíš nic bez zdroje. Pokud uvádíš číslo, musíš napsat odkud pochází. “PNO = 8 (zdroj: FACT_2025-01-15_ppc-q4-report)” je správně. “PNO je přibližně 10” je špatně.
Povinný audit dat před analýzou. Systém mi řekne, co má a co nemá. “Google Ads export: aktuální. Konverzní data: 7 dní staré. Competitive intelligence: chybí. Coverage: 65%. Varování: doporučení o market share budou mít nízkou spolehlivost.”
Automatická degradace confidence. Každé doporučení má vypočítanou míru spolehlivosti. Čerstvé zdroje přidávají body, staré zdroje ztrácí body, chybějící data strhávají body.
Neaktuální data. Atom z roku 2024 nemusí platit v roce 2026. Proto má každý atom pole valid_until a systém automaticky snižuje váhu starých informací.
Semafor spolehlivosti
Koncept semaforu jsem popsal v úvodním článku – každé doporučení má barvu podle spolehlivosti (🟢 HIGH → 🟡 MEDIUM → 🔴 LOW). Tady ukážu, jak to vypadá v praxi.
Příklad z praxe: “Které PPC kampaně vypnout?”
Tady je reálný příklad, jak systém reaguje na strategický dotaz. Zeptal jsem se: “Jaké kampaně v PPC máme vypnout a které posílit?”
Běžná AI by mi rovnou napsala doporučení. Můj systém nejdřív udělal audit dat:
Co systém viděl:
Zdroj Stáří Co obsahuje Spolehlivost
GA4 export konverzí 12 měsíců Konverze per kampaň (266 řádků) 🟡 PARTIAL
Knowledge base (100+ atomů) 0-9 měsíců Insighty, fakta, rozhodnutí 🟢 HIGH
Reporting PDF 35 dnů Agregované metriky 🟡 MEDIUM
Co systém označil jako kriticky chybějící:
- Google Ads export s NÁKLADY → “Nevím, kolik která kampaň STOJÍ”
- ROAS/CPA per kampaň → “Nemohu říct, co je rentabilní”
- Conversion VALUE → “Mám jen COUNT konverzí, ne hodnotu”
A/B srovnání výstupů:
S úplnými daty Bez nákladových dat
“Vypni kampaň X – CPA 850 Kč vs target 300 Kč” “Možná vypni X, nevím”
“Posil kampaň A – PNO 6 má kapacitu” “Kampaň A vypadá ok, asi”
Konkrétní přerozdělení budgetu Obecné best practices
Systém mi explicitně řekl: “Vidím počty konverzí, ale bez nákladových dat NEMOHU říct, která kampaň má nejlepší CPA. Chceš pokračovat s omezenou analýzou, nebo dodáš Google Ads export?”
Tohle je zásadní rozdíl. Běžný chatbot by sebevědomě doporučil “vypni kampaň s nejméně konverzemi” – jenže ta může mít nejlepší CPA. Můj systém přizná, že neví, a řekne mi přesně, co potřebuje.
Co budu dělat dál
Automatické tahání dat – Cíl je napojit systém na živé zdroje přes MCP – analytické platformy, reklamní systémy, SEO nástroje. Aby si agent mohl sám vytáhnout aktuální data místo toho, abych mu je ručně exportoval.
Vylepšování agentů – To mi přijde hodnotné. Já sám jsem generalista, vím od všeho něco, umím věci spojovat. Ale nejsem už dávno specialista na SEO, nebo na PMAX kampaně, nebo Reels. Mohu ale mít na to dost dobrého agenta, který mě jako stratégovi pomůže při rozhodování.
Optimalizace nákladů – S rostoucím využitím roste i cena za API volání. Existují techniky, jak dramaticky snížit náklady – systém může “cachovat” znalostní báze a neposílat je opakovaně.
Škálování – Současný systém funguje pro stovky atomů. Ale co až jich bude tisíce? Plánuji přidat chytřejší vyhledávání, které umí najít sémanticky podobné informace, ne jen přesné shody klíčových slov.
Napojit MCP - Napojit PPC agenty na Google Ads API (real-time kampáně), napojit analytické agenty na GA4 (live traffic data), napojit SEO agenty na Google Search Console (live indexace)
Systém pořád vyvíjím. Každý týden přidávám nové agenty, ladím workflow, učím se nové věci. Tohle není hotový projekt – je to živý nástroj, který roste s mými potřebami.
V dalším díle popisuji, co vím o Skills a Agentech a jak s tím můžete také začít.
Další články série
- 0: 20 let v marketingu – co vše AI v marketingu mění
- 1/3: Postavil jsem si Stínový kabinet
- 2/3: Jak jsem sestavil svůj Stínový kabinet - znalostní systém (tento článek)
- 3/3: Skills & agenti jako nový standard
Stavíte si podobné systémy? Máte pro mě doporučení, jak mohu svůj systém vylepšit. Ozvěte se a nasdílejte.

